All files used in the following examples can be downloaded from here |
|
Evaluate an existing MSA |
t_coffee -infile prot.aln -evaluate -output score_ascii, aln, score_html
|
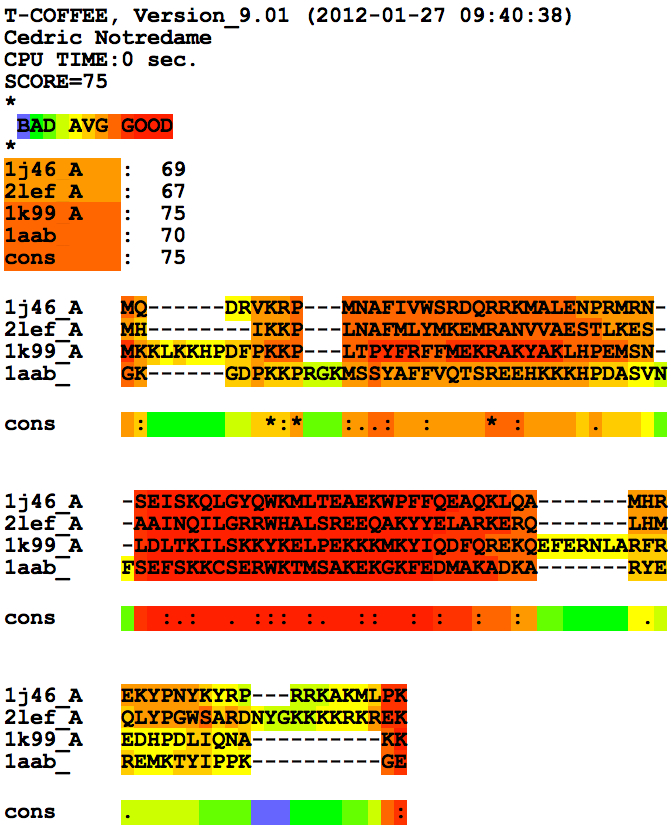
prot.score_ascii: displays the score of the MSA, the sequences and theresiues. This fille can be used to further filter your MSA with seq_reformat |
prot.score_html: displays a colored version score of the MSA, the sequences and the resiues. |
|
Filter unreliable MSA positions |
t_coffee -infile prot.aln -evaluate -output tcs_residue_filter3, tcs_column_filter3, tcs_residue_lower4 |
prot.tcs_residue_filter3: All residues with a TCS score lower than 3 are filtered out |
prot.tcs_column_filter3: All columns with a TCS score lower than 3 are filtered out |
prot.tcs_residue_lower4: All residues with a TCS score lower than 3 are lower cased |
Note that all these output functions are also compatible with the default T-Coffee when computing an alignment: |
t_coffee -seq prot.fa -output tcs_residue_filter3, tcs_column_filter3, tcs_residue_lower4 |
Or with seq_reformat using a T-Coffee .score_ascii file |
t_coffee -other_pg seq_reformat -in prot.aln -struc_in prot.score_ascii -struc_in_f number_aln -output tcs_residue_filter3 |
|
Weight MSA positions for Improved Trees |
t_coffee -infile prot.aln -evaluate -output tcs_weighted, tcs_replicate_100 |
prot.tcs_weighted: All columns are duplicated according to their TCS score |
prot.tcs_replicate_100:Contains 100 replicates in phylip format with each column drawn with a probability corresponding to its TCS score |
Note that all these output functions are also compatible with the default T-Coffee when computing an alignment: |
t_coffee -seq prot.fa -output tcs_weighted, tcs_replicate_100 |
Or with seq_reformat using a T-Coffee .score_ascii file |
t_coffee -other_pg seq_reformat -in prot.aln -struc_in prot.score_ascii -struc_in_f number_aln -output tcs_weighted |
|
Work with coding DNA |
When working with DNA, it is advisable to first align the sequences at the protein level and later thread back the DNA onto your aligned proteins. The filtering must be done in two steps, as shown below. Note that your DNA and protein sequences must have the same name |
t_coffee -infile prot.aln -evaluate -output score_ascii |
This first step produces the TCS evaluation file prot.score_ascii |
t_coffee -other_pg seq_reformat -in prot.aln -in2 dna.fa -struc_in prot.score_ascii -struc_in_f number_aln -output tcs_replicate_100 -out dna.replicates |
dna.replicates: 100 DNA replicates with positions selected according to their AA TCS score |
t_coffee -other_pg seq_reformat -in prot.aln -in2 dna.fa -struc_in prot.score_ascii -struc_in_f number_aln -output tcs_column_filter5 -out dna.filter |
dna.filtered: DNA positions filtered according to their TCS column score |
|
Using Different TCS Libraries |
| It is possible to change the way TCS reliability is estimated. This can be done by building different T-Coffee libraries. The following instructions will do this. |
t_coffee -infile prot.aln -evaluate -method proba_pair -output score_ascii, aln, score_html |
| proba_pair is the default mode of T-Coffee that runs a pair-HMM to populate the library with residue pairs having the best posterior probabilities. |
t_coffee -infile prot.aln -evaluate -method mafft_msa,kalign_msa,muscle_msa -output score_ascii, aln, score_html |
| This mode runs a series of fast multiple aligners. It is very fast and used by ENSEMBL Compara |
t_coffee -infile prot.aln -evaluate -method clustalw_pair,lalign_id_pair -output score_ascii, aln, score_html |
| This mode runs the orginal default T-Coffee that was combining local and global alignments. |
|
Summary of the Various Output Flags |
-output=score_ascii | outputs a TCS evaluation file |
-output=tcs_residue_filterN | Removes all residues with a TCS score lower than N |
-output=tcs_columns_filterN | Removes all columns with a TCS score lower than N |
-output=tcs_weighted | Duplicates all columns according to their TCS scoreN, The output is in Phylips |
-output=tcs_replicateN | Generates N phylips replicates, with columns drawn according to their TCS score |
-output=..._fasta | Generates the replicates or filtered output in FASTA |
-output=..._rphylip | Generates the -replicates or filtered output in a relaxed Phylip where names can be longuer than 10 char |
|
|